A Rede Neural¶
De início, uma rede neural pode parecer um emaranhado de conexões sem sentido, difíceis, à olho nu quase impossíveis, de interpretar. Mas lembra que ela foi inspirada no cérebro? Nada funciona sozinho. Tudo faz parte de um sistema complexo, interconectado e adaptável.
Multilayer Perceptron (MLP)¶
Estrutura de uma Rede Neural¶

Camada¶
Uma camada é um conjunto de neurônios que recebe um mesmo tipo de entrada, aplica a mesma lógica básica, Wx + b seguida de ativação, e produz um novo conjunto de saídas. Essas saídas alimentam a próxima camada da rede.
Intuitivamente, você pode visualizar uma camada como um conjunto de neurônios em paralelo. Todos realizam a mesma operação, apenas os parâmetros são diferentes.
A rede¶
Um MLP é composto por 3 tipos de camadas:
-
Camada de Entrada (Input Layer): Recebe os dados brutos. Cada neurônio representa uma característica (feature) dos dados de entrada, por exemplo, pixels de uma imagem ou colunas de uma tabela.
-
Camada Oculta (Hidden Layer): Transforma as informações recebidas em representações cada vez mais abstratas. Pode haver uma ou mais camadas ocultas, cada uma com um número variável de neurônios. É aqui que a rede aprende: por meio de pesos (weights), funções de ativação e o algoritmo de backpropagation (veremos isso em breve).
-
Camada de Saída (Output Layer): Produz o resultado final. O número de neurônios depende da tarefa: um único neurônio para classificação binária, múltiplos para classificação multiclasse, ou valores contínuos para regressão.
Teorema de Aproximação Universal
Uma rede neural com pelo menos uma camada oculta e neurônios suficientes pode aproximar qualquer função contínua com precisão arbitrária.
Na prática, isso significa que um MLP tem capacidade teórica de modelar qualquer relação entre entrada e saída: desde que tenha arquitetura adequada e seja bem treinado. Por isso, MLPs são considerados Turing-completos: capazes de computar qualquer função computável. O limite não é teórico, é prático — recursos finitos, dados finitos, tempo finito.
A arquitetura básica da rede consiste em enfileirar camadas e, com essa estrutura, "atravessar" dados pela rede para produzir a saída, da camada Input até a camada de Output. Mas como isso é feito?
O processo de inferência: Forward Propagation¶
Forward Propagation (Propagação Direta) é o processo pelo qual uma entrada percorre toda a rede neural, camada por camada, até produzir uma saída final. É literalmente como os dados "fluem para frente" através da rede.
Como os neurônios se conectam¶
Matematicamente, cada camada realiza uma transformação linear seguida de ativação:
Onde:
- \(\mathbf{W}^{[l]}\): matriz de pesos da camada \(l\)
- \(\mathbf{b}^{[l]}\): vetor de bias da camada \(l\)
- \(\mathbf{a}^{[l-1]}\): ativações da camada anterior
- \(f()\): função de ativação (ReLU, Softmax, etc.)
Pense nisso como o seguinte:
- Cada neurônio calcula uma soma ponderada das entradas, com pesos e bias.
- Aplica a função de ativação para introduzir não-linearidade.
- Passa a ativação para a próxima camada.
No caso do MLP, a saída de cada neurônio de uma camada torna-se entrada para todos os neurônios da próxima camada. Por isso, o MLP também é um tipo de fully connected neural network (FCNN, ou rede neural totalmente conectada).
O processo passo a passo¶
Vamos rastrear como uma imagem de 28×28 pixels passa pela nossa rede em um problema de classificação binária:
Mas antes, como uma imagem pode ser a entrada de uma rede neural?
Para um humano, uma imagem é algo visual: um gato, um número, uma mosca. Para a rede, não. Ela enxerga apenas números.
Uma imagem em escala de cinza é na prática uma grade de pixels, ou seja, uma matriz, e cada pixel é um número que representa intensidade de luz. Quanto mais claro o pixel, maior o valor; quanto mais escuro, menor.
Então a ideia central é simples: a imagem não entra na rede como "desenho", mas como uma lista de intensidades numéricas. Em um MLP, normalmente achatamos a matriz 28 × 28 em um vetor com 784 valores. Cada um desses valores vira uma entrada para um neurônio da camada inicial.
A intuição correta é essa: antes de reconhecer padrões, a rede recebe apenas uma coleção organizada de números. O que chamamos de "imagem" é uma interpretação nossa; para o modelo, é só um vetor que precisa ser transformado em algo mais útil.
A arquitetura¶
A arquitetura da rede é definida pela largura (quantos neurônios) de cada camada, a profundidade (quantas camadas) e como estas camadas estão conectadas (tipo da rede). No caso do MLP, as camadas estão totalmente conectadas.
Para o problema hipotético, foram definidas as seguintes dimensões para a rede:
-
Camada 1 (Input Layer): ?
-
Camada 2 (Hidden Layer): 128 neurônios
-
Camada 3 (Hidden Layer): 64 neurônios
-
Camada 4 (Output Layer): ?
Considerando que o modelo quer fazer a classificação binária de uma imagem 28x28:
Quantos neurônios deve ter a camada de entrada?
Cada neurônio da camada de entrada recebe uma feature dos dados de entrada. No caso da imagem, as features são os pixels, então precisamos de um neurônio para cada pixel. Portanto, são 784 neurônios.
Quantos neurônios deve ter a camada de saída?
Cada neurônio produz uma única saída, um valor. Se o problema é de classificação binária, precisamos de apenas um valor: a probabilidade da entrada ser da classe positiva. Portanto, apenas 1 neurônio.
Etapas da inferência¶
Passo 1: Preparação da entrada
A entrada original é uma matriz 28 × 28, isto é, uma imagem. Antes de entrar no MLP, ela é transformada em um vetor 784 × 1 por meio de flatten e normalização.
Passo 2: Primeira camada oculta
Primeiro, a rede aplica uma transformação linear sobre a entrada:
Depois, aplica a função de ativação:
Passo 3: Segunda camada oculta
A ativação da camada anterior vira a entrada da próxima:
Passo 4: Camada de saída
Por fim, a última camada transforma essas ativações em uma probabilidade:
Dimensões das matrizes¶
Para nossa arquitetura, 784 → 128 → 64 → 1:
- W₁: 128 × 784 (cada linha = pesos de um neurônio)
- b₁: 128 × 1 (um bias por neurônio)
- W₂: 64 × 128
- b₂: 64 × 1
- W₃: 1 × 64
- b₃: 1 × 1
Representação matemática completa¶
Resultado
\(\mathbf{a}^{[3]}\) representa a probabilidade prevista para a classe positiva.
Backpropagation: Treinamento de Redes Neurais¶
Você já sabe que o gradiente descendente é o mecanismo que ajusta os pesos da rede. Mas surge uma pergunta prática: a rede pode ter milhões de pesos. Como calcular o gradiente de cada um deles de forma eficiente?
É exatamente isso que o backpropagation resolve.
Vídeo
Se tiver tempo, assita o vídeo a seguir do 3Blue1Brown, ajudará a criar intuição sobre o processo de treinamento de Redes Neurais:
Cálculo do Custo¶
Antes de ajustar qualquer coisa, a rede precisa saber o quanto errou.
Pensa assim: a rede chutou um valor, e você tem a resposta certa. A função de custo (cost function/) é simplesmente uma forma de medir essa distância entre o chute e a resposta. Uma das mais usadas é o Erro Quadrático Médio (MSE):
Onde \(\hat{y}\) é o valor previsto pela rede e \(y\) é o valor real. Quanto maior a diferença, maior o valor de \(\mathcal{L}\).
Lembrando: Por que elevar ao quadrado?
Dois motivos simples. Primeiro: errar por +3 é tão ruim quanto errar por -3, e o quadrado elimina o sinal negativo. Segundo: erros grandes são punidos muito mais do que erros pequenos. Um erro de 10 vira 100. Um erro de 1 continua sendo 1. Isso faz a rede se preocupar mais com os erros graves.
Como o Erro Chega em Cada Peso¶
Agora vem a parte central do backpropagation.
O gradiente descendente precisa saber: "se eu mudar esse peso específico um pouquinho, o erro aumenta ou diminui?" Isso é a derivada parcial do erro em relação àquele peso, \(\frac{\partial \mathcal{L}}{\partial w}\).
O problema é que os pesos das primeiras camadas não afetam o erro diretamente. Eles afetam a próxima camada, que afeta a seguinte, que finalmente afeta a saída. É uma cadeia.
Para calcular a derivada nessa situação, usamos a regra da cadeia do cálculo. O backpropagation aplica essa regra de forma inteligente: começa calculando o gradiente na camada de saída, onde o erro é conhecido, e vai passando esse gradiente para trás, camada por camada, até chegar na entrada.
É por isso que se chama backpropagation: a informação do erro se propaga de trás para frente.

Vídeos
Não entraremos em detalhes aqui sobre o cálculo do backpropagation, já que não implementaremos manualmente esse cálculo. Se tiver interesse, assista esses vídeos do 3Blue1Brown, você entenderá como tudo funciona:
Visualização Interativa¶
Veja ao vivo como a rede ajusta os pesos durante o treinamento. Observe o erro caindo e as regiões de decisão se formando gradualmente:
Se o playground não carregar
Acesse diretamente em playground.tensorflow.org.
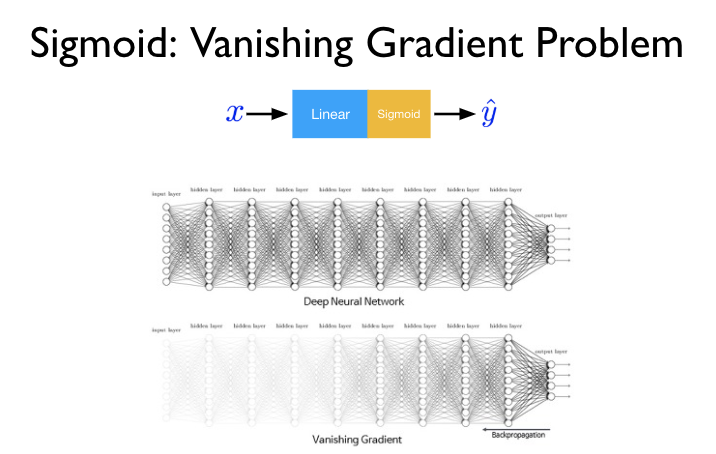
Vanishing Gradient¶
O backpropagation passa o gradiente da saída até a entrada, camada por camada. Em redes rasas, isso funciona bem. Mas em redes profundas, aparece um problema sério.
Pensa numa corrente de pessoas passando um bilhete. Cada pessoa lê o bilhete, reescreve com letra menor, e passa adiante. Quando chega na primeira pessoa da fila, o bilhete está tão pequeno que ela mal consegue ler. É exatamente isso que acontece com o gradiente em redes profundas.
O culpado costuma ser a função de ativação. A sigmoide, por exemplo, comprime qualquer valor para o intervalo \((0, 1)\). A derivada dela tem valor máximo de \(0.25\). Como o backpropagation multiplica essas derivadas camada por camada pela regra da cadeia, o gradiente encolhe exponencialmente:
Efeito prático
As primeiras camadas da rede recebem um gradiente tão pequeno que seus pesos praticamente não se atualizam. A rede para de aprender nas camadas mais profundas, o treinamento estagna e o modelo final fica fraco, mesmo com uma boa arquitetura.
Como resolver?¶
As principais soluções que surgiram para esse problema são:
| Solução | Como ajuda |
|---|---|
| ReLU (e variantes) | Derivada constante igual a 1 para valores positivos, sem compressão do gradiente |
| Batch Normalization | Normaliza as ativações entre camadas, evitando que os valores explodam ou somam |
| Inicialização cuidadosa dos pesos | Técnicas como He (para ReLU) e Xavier (para tanh) que partem de um ponto mais estável |
| Redes residuais (ResNets) | Conexões que pulam camadas inteiras, criando atalhos diretos para o gradiente |
Experimente no Playground
Troque a função de ativação de sigmoid para ReLU no playground acima e compare a velocidade de convergência. Você vai ver a diferença na prática.